Fastai Week 1 Classifying Camels Horses And Elephants

Intro
The third iteration of the fastai course, Practical Deep Learning for Coders, began this week. I am one of 2,000 International Fellows for the course which means we are able to join remotely and tuition-free. We have access to live videos and the fastai Discourse Forums. The live, in-person, course is at University of San Francisco (USF), where about 300 students are attending.
The course uses the recent release of fastai version 1.0 and PyTorch 1.0, which are both cutting edge. The MOOC is set to be released in early 2019.
Work In Progress
The fastai library and documentation are being updated as the course progresses. Patience is important as students share progress as well as glitches encountered. Anyone is welcome to contribute to the library, as it is open source. Learning to search the Forums and google errors are important skills to master.
💡Therefore, it is of upmost interest to be working with the latest version of the fastai library: git pull
New York City (NYC) Study Group
I participated in last year’s (Fall 2017 version 2) online course. Due to mobility issues related to my ankle, I was unable to meet NYC participants in person. Since then, I had ankle surgery this past spring. I am now mobile enough to meet NYC fastai learners in person!
Each region, based on timezone, has study groups. The NYC study group met, for the first time, for this course, this past Monday, just a few hours prior to the first livestream lesson (22-Oct-2018). The lectures are live at 9:30pm to midnight (EST). Special thanks to IBM and Galvanize for providing the space. One of our members, German, had met Soumith Chintala at an event and invited Soumith to our study group. It was a real treat to meet and chat with the creator of PyTorch. There were 10 of us in the study group, so we had a casual 2-hour discussion, taking the opportunity to meet everyone in person and ask Soumith any questions we had about PyTorch, its development and its future. NYC is an amazing place to live and which permits us access to resources and people. What a privilege to live in this bustling city!


Lesson 1 Homework
In the course last year, I mainly watched the videos, created documentation and followed the Forums discussion. This time, I was excited about entering the course with some familiarity and being better prepared to do the assignments. The documentation and tutorials that are available in this iteration make the course significantly more accessible. Before I began training a neural net on my own dataset, I did the following:
Preparation / Homework: parts completed ✅
- Google Cloud setup
- Get GPU going
- read lesson1 notebook
- read Lesson 1 notes (link is not public yet)
- read tutorial on creating own Image dataset using Google Images
- read fastai documentation
- run lesson1-pets Jupyter notebook, which was presented in Lecture 1, to ensure all code runs without errors
When I ran into errors, I would search the Forums or Google it. I was able to proceed!
Dataset
Our Lesson 1 homework is to obtain our own data and train a classifier to distinguish between two objects. I am enchanted by camels, ever since my trip to Morocco nearly 15 years ago! So, I chose camels and horses.


I began with a small sample, only 50 images in each class. URLS of images, in a .csv file, were downloaded to my local computer using Google Images and Chrome extension: download all images. I uploaded the files to Google Cloud Platform (GCP) using the scp (Secure Copy) command.
This is how the urls are stored in the text file:
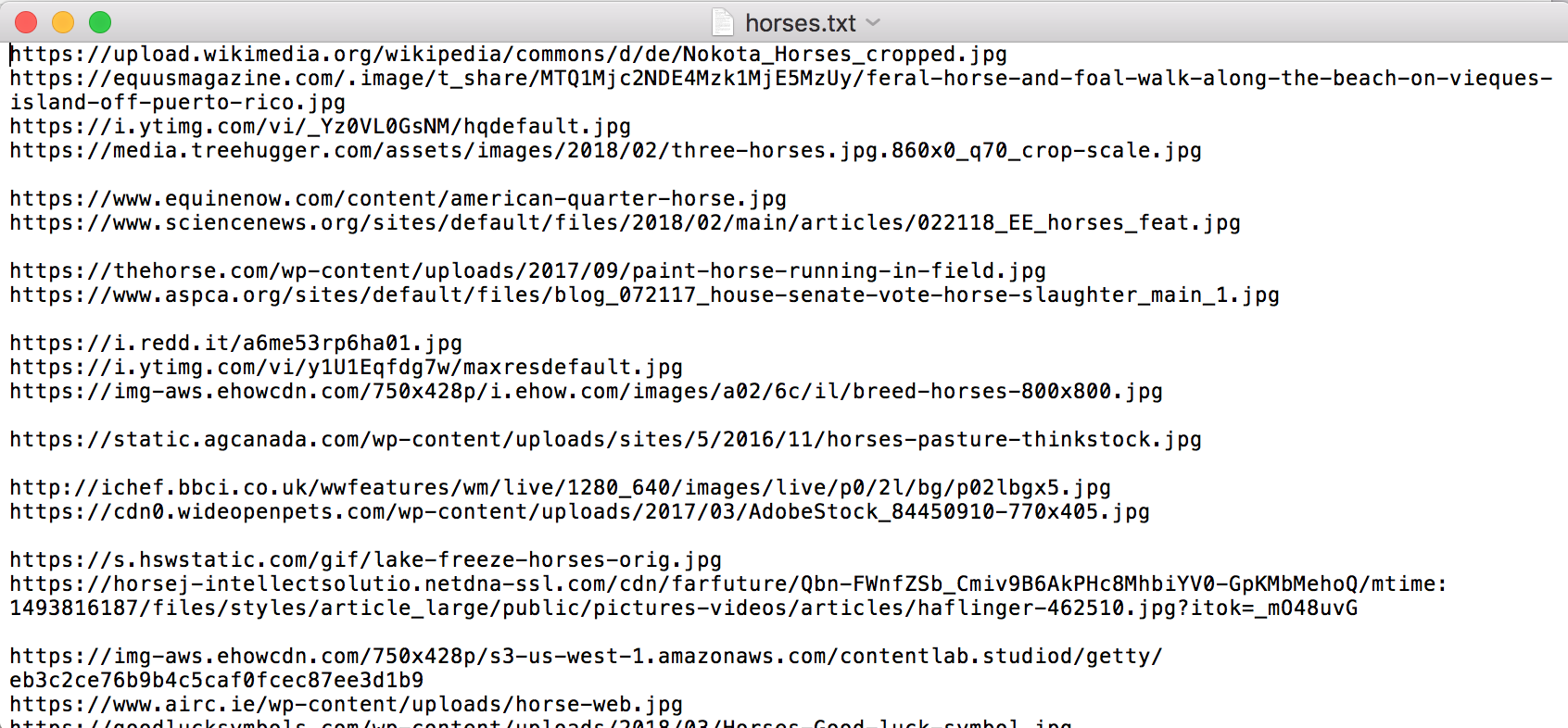
I converted the file to .txt so it would be consistent with what was used in the course notebooks. I also renamed the files and moved them to the appropriate folders.
Google Cloud Platform
This was my first time using Google Cloud Platform (GCP). Previously, I have used AWS, but since I ran out of credits, I decided to give GCP a try. It certainly helps to have some experience with one cloud platform. I attempted to upload the urls text file from my local computer up to GCP using commands I had previously used with AWS, but received an error. A quick search in Google yielded that I needed to update my code:
- AWS:
scp -r urls_horses.txt ubuntu@111.11.111.411: - GCP:
gcloud compute scp urls_horses.txt jupyter@my-fastai-instance:~
Based on my recent use of GCP, it looks like many commands begin with gcloud or gcloud compute.
gcloud --version
gcloud auth login
gcloud compute ssh --zone=us-west2-b jupyter@my-fastai-instance -- -L 8080:localhost:8080
gcloud compute scp urls_horses.txt jupyter@my-fastai-instance:~
Result for Camels / Horses
I used a small dataset, about 80 images. I used a CNN pre-trained model, and trained for 4 epochs (number of passes through the data). The architecture used was resnet34. Below are my results:
learn = learner.create_cnn(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)
Total time: 00:35
epoch train_loss valid_loss error_rate
1 1.220116 0.686683 0.285714 (00:09)
2 0.807073 0.375571 0.103896 (00:07)
3 0.640212 0.295698 0.051948 (00:09)
4 0.556612 0.225274 0.051948 (00:08)
The error rate was 5.2%, which is pretty good!
Next, since this was a pre-trained model, I can train the last layers by unfreezing them, finding a learning rate and more learning.
learn.unfreeze()
learn.lr_find(stop_div=False)
learn.recorder.plot()
learn.fit_one_cycle(2, max_lr=slice(1e-4,1e-3))
Total time: 00:17
epoch train_loss valid_loss error_rate
1 0.169633 0.141895 0.064935 (00:09)
2 0.138307 0.179179 0.038961 (00:08)
The error rate is now reduced to 3.9%.
A closer look at the classification shows that only 3 images were mis-classified, and for all 3, they were predicted to be horses, but were actually camels.
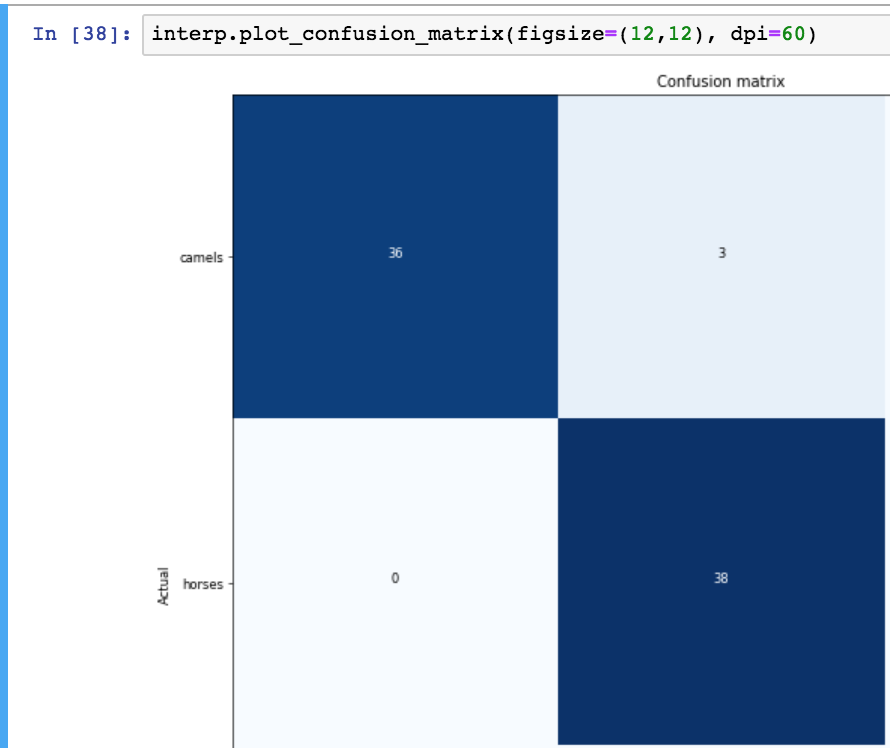
Here is the confusion matrix.
- 36 camels were classified correctly
- 38 horses were classified correctly
- 3 camels were misclassified as horses
Here we can see the first row shows the 3 missclassified images. The first image has the highest loss, where we see the man holding the camel’s head. The numbers at the top of the images represent, in this order:
- prediction label
- actual label
- loss
- probability it was predicted

References
- My work in progress is here: dl_fastai
Next Steps
In retrospect, it is quite easy to tell the difference between camels and horses. Let’s challenge the neural network with something more difficult to discern, even for a human… Perhaps classifying African and Asian elephants…
Tweets
Full house at the first class of #DeepLearning4Coders + 3k students live steaming from all over the world @DataInstituteSF @fastdotai @jeremyphoward @math_rachel pic.twitter.com/2xcjecGcy4
— Ignacio López-Francos (@iglpzfr) October 23, 2018
Leave a Comment