Data Umbrella Scikit Learn Online Sprint Report


Sprint Background
This sprint was organized by Reshama Shaikh of Data Umbrella and NYC PyLadies to increase the participation of underrepresented persons in data science. All organization of this sprint was by volunteer time.
The sprint was originally scheduled to be an in-person event in New York City. It would have been the fourth year in a row that I (Reshama Shaikh) would have organized a sprint in NYC. Due to the coronavirus pandemic, it was pivoted to become a virtual event.
This report focuses on the summary, impact and lessons learned of the first online scikit-learn sprint.
Demographics
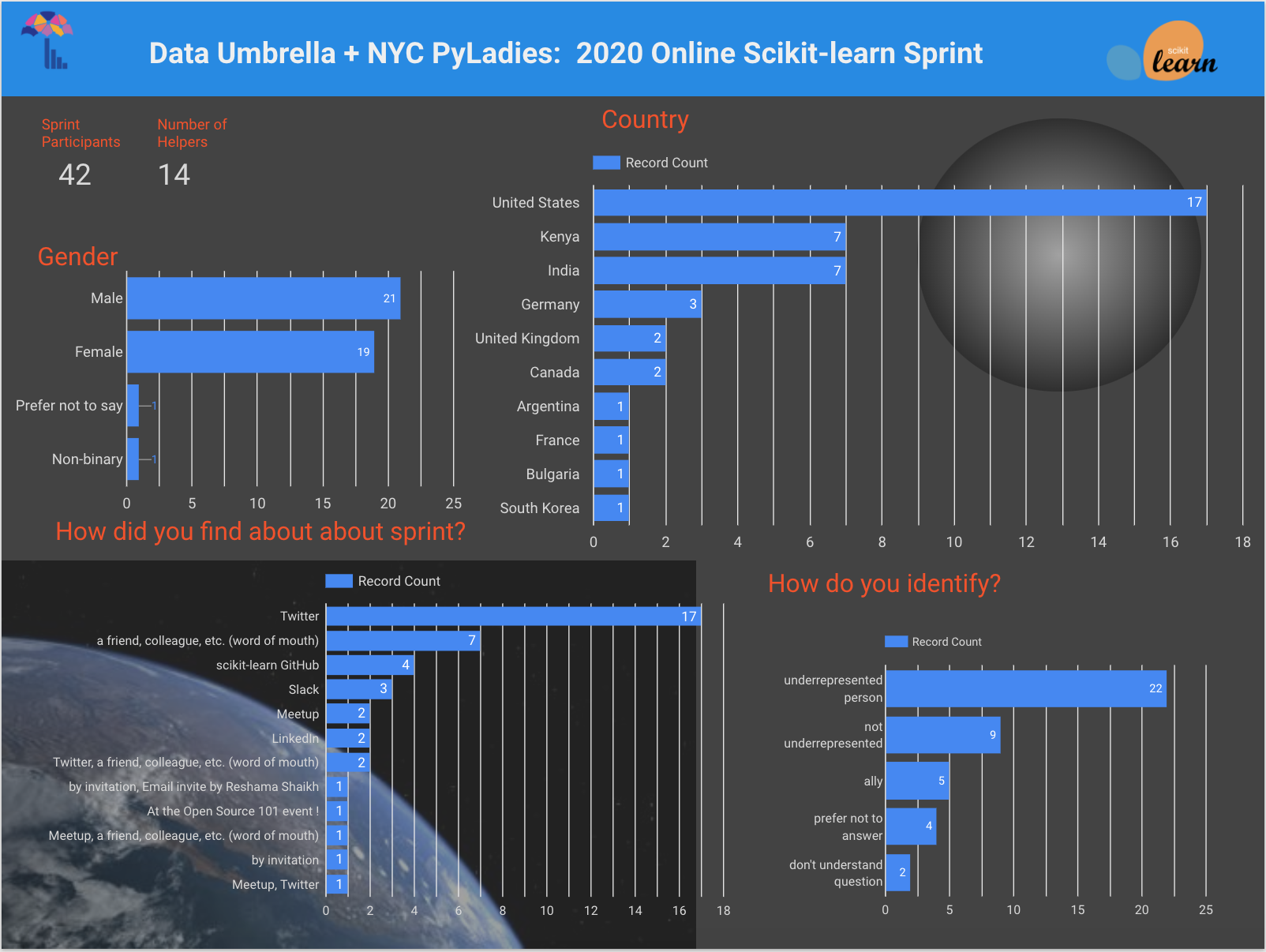
To ensure that attendees had some knowledge of Python and scikit-learn, a brief application form was used. Attendees did not have to be experienced Git users, but some experience was helpful.
About 25% of the attendees had participated in a scikit-learn open source sprint before. The attendees were evenly split by gender. Participants from ten different countries joined. Over half the participants identified as “underrepresented.”
Most attendees learned of the event via Twitter and word-of-mouth, followed by scikit-learn GitHub repo and then through other social media and community platforms (e.g. Slack, Meetup, LinkedIn, etc.)
Impact Report for Data Umbrella Scikit-learn Sprint
| Sprint 2020 | |
|---|---|
| Report date | 27-Jun-2020 |
| Sprint date | 06-Jun-2020 |
| Location | Online; Global |
| Sprint website | 2020 Online Sprint |
| Twitter Moment | |
| Open source library | scikit-learn |
| GitHub repository link | data-umbrella/2020-sklearn-sprint |
| List of Issues | project list |
| Organizer | Reshama Shaikh |
| Lead Facilitator | Andreas Mueller |
| Scikit-learn core contributors | Adrin Jalali, Thomas Fan, Nicolas Hug, Chiara Marmo, Tom Dupre la Tour |
| Teaching Assistants | Mark Hannel & Shashank Singh |
| Helpers | Mariam Haji, Noemi Derzsy, Melissa Ferrari |
| Platforms | Discord & Zoom |
| Sponsor: venue | Not applicable |
| Sponsor: food | Not applicable |
| Cost of Sprint | 60 hours volunteer time to organize event |
| PULL REQUESTS (PRs) | |
| PRs [MRG] at sprint | 27 |
| PRs [MRG] post-sprint | 30 |
| PRs open | 4 |
| PRs returned to issue pool | ? |
| TOTAL PRs MERGED | 57 |
| PRs merged | |
| PRs open | |
| Attendees: Initial Registrations | 51 |
| Attendees: Participated | ~ 42 |
| Attendee List | 2020 |
| Post-sprint Survey | survey form (closed) |
| Blog 1: by Joe Lucas | Scikit-learn Sprint: My Open Source Adventure |
| Blog 2: by Jake Tae | A Reflection on My First Open Source Contribution Sprint |
| Blog 3: by C Thinwa | Why you should contribute to open-source as a data scientist |
| Blog 4: by Maren Westerman | Review of the Data Umbrella Scikit-learn Online Sprint June 2020 |
Impact Summary for 2020
Some stats on today's ONLINE @DataUmbrella #ScikitLearnSprint:
— Reshama Shaikh (@reshamas) June 6, 2020
• 27 PRs MERGED!
• 27 PRs still *open* (TBC) (⚖️)
• 42 new & returning contributors
• 13 helpers
• ➕➕❤️ the contributors emojis!
Thanks to all for spending this Saturday across 16 different time zones with us! pic.twitter.com/MhrjtkMsui
Preparation Work
Because this was a virtual event and the idea of having an 8-hour online sprint was not appealing (to me), I reduced the time in half and increased the preparation work that attendees could do.
There are two videos for newcomers to Get Started with Contributing to Scikit-learn:
- Andreas Mueller: Crash Course in Contributing to Scikit-learn
- Reshama Shaikh: Contributing to Scikit-Learn: An Example Pull Request
Added Bonus: Many people who discovered these resources from social media and were not participating in the sprint watched the videos and began submitting PRs. The goal was to make contributing accessible to a larger pool of people.

Challenges for Me, as an Organizer
Participants can use a variety of different (user) names (and nicknames) for email, Discord, GitHub, social media, etc. It is challenging to connect their different profiles and assist them, and it makes getting to know participants more time-consuming and difficult.
Challenges
Technology Platforms
For a typical in-person sprint, interaction is in person and some communication in the scikit-learn sprint Gitter channel.
For the virtual event, the following platforms were utilized, which would also limit any costs required to use:
- Zoom: for presentation: being online from 11:45 am EDT to about 12:15 pm EDT (because Discord has max of only 25 people in any one channel, and we have about 50 people joining)
- Discord: during sprint time
- Gitter: use after sprint (Typically our sprints are in person, so sprint participants would ask in person or on Gitter.) There are more core scikit-learn contributors on Gitter than on this Discord. But, typically, if the question is related to a specific pull request (PR), the conversation is on the GitHub PR.
Pair Programming
About 8 people were no-shows, and their pairs needed to be reassigned at the start of the event.
Discord
Discord is a platform which is unfamiliar to some people and there was a learning curve in navigating it.
Applicant Responsivity
Over 80 applicants were sent acceptances and half did not RSVP. Partial reasons is that the sprint emails were going to spam folders.
Virtual Environment Setup for Windows
A number of Windows users experienced challenges in setting up their virtual environment.
Pair Programming
This was an entirely online event. Participants were assigned their partner prior to sprint start. Where possible, a new contributor was matched with a returning contributor.
Follow-up Office Hours
Office hours were set up 2 weeks after the sprint where some of the scikit-learn core contributors were available to answer questions on open PRs. The office hours were scheduled for 7am PDT / 10am EDT / 5pm EAT / 7:30pm IST.
Non-measurable Impact
Aside from the number of PRs that were merged, there is non-quantifiable impact of the open source sprint. Some examples include:
- learning to set up virtual environment
- using Git (fork, clone, branch, fetching another’s PR)
- introduction to tests such as: flake8 (linting, formatting), pytest, “continuous integration”
- navigating through the codebase structure of scikit-learn
- digging into functions, learning about errors
- learning about unit tests
- interacting with contributors on GitHub
- learning, in general
- networking
- building confidence (making a dent in “imposter syndrome”)
- having fun
Sprint Feedback
Feedback has been shared a number of ways:
- Twitter Moment
- Blogs
- Sprint survey
- Casually, in conversation during the sprint
Such an amazing feeling when you solve an issue on Scikit learn and your PR gets merged 😍.
— Mariam Ahmed (@MamuAhmed) June 11, 2020
Thank you @reshamas for introducing me in to open source contribution, @adrinjalali & @amuellerml for your patience till I somehow got it right. #ScikitLearnSprint
I wrote a blog about my experience of taking part in the recent #opensource online #ScikitLearnSprint. A big thank you to everyone involved in organising the sprint for your time and support! Link to my blog is below 👇🏾 https://t.co/fF5drTcQzY
— Dr Maren Westermann (@MarenWestermann) June 12, 2020
First time contributor Cynthia Thinwa joined the @DataUmbrella & @NYCPyLadies online #ScikitLearnSprint from Nairobi, Kenya.
— Reshama Shaikh (@reshamas) June 12, 2020
She had a wonderful experience and shares why it's good for data scientists to contribute to open source.https://t.co/LOFydjpL0b
The first online #ScikitLearnSprint began at noon, EDT. For @jaesungtae, who was joining from Korea (at 1am!), it was already the next day🌏.
— Reshama Shaikh (@reshamas) June 10, 2020
That is enthusiasm for #python, @scikit_learn & #opensource!
Read about his sprint day here:https://t.co/EfrFQysk2J https://t.co/jWExm4kUPL
This weekend, I participated in @DataUmbrella's & @NYCPyLadies's #ScikitLearnSprint. First time contributing to this project & it comes w/ the nervous excitement of being a newbie here and learning a new codebase. thanks @thomasjpfan for the review and for the help! PR merged :) https://t.co/EQvXTtuaeQ
— teon 🖤🌹🏳️🌈✊🏾 (@teonbrooks) June 8, 2020
I learnt a lot solving small issues with my #ScikitLearnSprint team mate @pardeepshergill!
— Violeta Roizman (@violetrzn) June 6, 2020
Thanks a lot to the core developers and organizers!
Huge shout-out to @DataUmbrella and the @scikit_learn team for the online #ScikitLearnSprint. My pair partner Cynthia and I learned a lot, did our first-time PRs (that documentation will never be the same :) and we are hooked to open-source for life.
— Krum Arnaudov (@ArnaudovKrum) June 6, 2020
#ScikitLearnSprint is about to start and I'm double stoked by it. It's new community for me, and the sprint is a refreshingly diverse, global crowd. And I'm certain I'll learn a lot that can be used for future virtual sprints and hackweeks. Thanks @DataUmbrella @NYCPyLadies
— Brigitta Sipőcz (@AstroBrigi) June 6, 2020
Special "Thank you!" to both @reshamas and @amuellerml - I was really anxious and your Beginner Resources helped me bridge the first-time block. I will try my best to pay back in pull requests and word spreading :) You are great!
— Krum Arnaudov (@ArnaudovKrum) June 6, 2020
Two pull requests, an comment, and an issue submitted..
— Lauren Oldja (@urbanplans) June 6, 2020
Pair programming works! :)
Thanks so much @reshamas @DataUmbrella @MelissaFerrari_ @NoemiDerzsy for organizing & @amuellerml @thomasjpfan @adrinjalali @hug_nicolas for facilitating#scikitlearn #opensource
Adjustments for Next Sprint
Application Form: reminder for spam
Remind participants that communication is sent from other platforms (Mailchimp, Eventbrite, etc) and it may go to spam. It would be good to keep an eye out on the spam folder or email the sprint organizer if they have not heard back.
Application Form: pronouns
Ask for preferred pronoun on application and also to include on website for contributors.
Issues
Add in a slide to explain to participants how to look for issues to work on.
Pair Programming
Add in a slide explaining how pair programming works.
Second Pull Request
Update slides / documentation to show how to submit a second PR.
Pair Partner
Explore how to optimally match participants as pair partners based on experience.
Platforms
Three platforms (Zoom, Discord and Gitter) were confusing for attendees. One platform was preferred.
Scikit-learn Mailing List
Include link to scikit-learn mailing list in communications. Encourage participants to sign up for the mailing list to keep up to date on discussions. The mailing list is also a good way to learn about open source, the library and the community. https://mail.python.org/mailman/listinfo/scikit-learn
Setting up virtual environment
We encouraged people to set up their virtual environment beforehand. The dilemna here is if we make it optional, more people probably would not do it. If we make it required, people who do not set up beforehand may not attend the sprint. Some people had difficulty setting up their environment and thought they could only join the sprint if their set up was ready. Action: find a way to optimize set up before the sprint while providing support for those who need it.
Discord categories
For each virtual table, use categories to group table for chat and voice. The current setup does not have voice and chat for each table adjacent to each other.
References
Query for PR:
- Open PRs: 4 (Query:
is:pr is:open created:>=2020-06-04 #DataUmbrella)- Open (w/o date range)
- Merged PRs: 57 (Query:
is:pr is:merged created:>=2020-06-04 #DataUmbrella)- Merged (w/o date range)
Addendum
- [no addendums or updates at the time of publication]
Leave a Comment