Data Umbrella Afme 2021 Scikit Learn Sprint Report

Sprint Background
This “sprint” is a hands-on hackathon where participants learn to contribute to scikit-learn, a widely-used Python open source, machine learning library.
This sprint was organized by Data Umbrella to increase the participation of underrepresented persons in data science, with a focus on the geographic regions of Africa and the Middle East (AFME).
This report focuses on the summary, impact and lessons learned of the Data Umbrella AFME scikit-learn sprint.
Event Sponsor
This event was funded in part by a grant from Code for Science & Society, made possible by grant number GBMF8449 from the Gordon and Betty Moore Foundation.
![]()
![]()
Continued Contribution to Open Source
This sprint was a 4-hour block of time with pre- and post-sprint work required.
Participants were encouraged to keep contributing to scikit-learn or other Python libraries, using the skills learned in this event.
Sprint Agenda
- 30-Jan-2021: pre-sprint Kickoff (10am to 11am EAT) [a]
- 06-Feb-2021: Sprint (10am to 2pm EAT)
- 20-Feb-2021: Sprint Follow-up Office Hours (10am to 11am EAT)
[a] EAT = East Africa Time
Sprint Day
The sprint officially ran 4 hours (10am to 2pm EAT), which is limited time to submit a PR. The participants continued to work on their sprint PRs throughout the day and weekend. Also, many scikit-learn core contributors were online to review the PRs over the weekend and provide feedback.
Follow-up Office Hours
Office hours were set up 2 weeks after the sprint where some of the scikit-learn core contributors were available to answer questions on open PRs.
Demographics
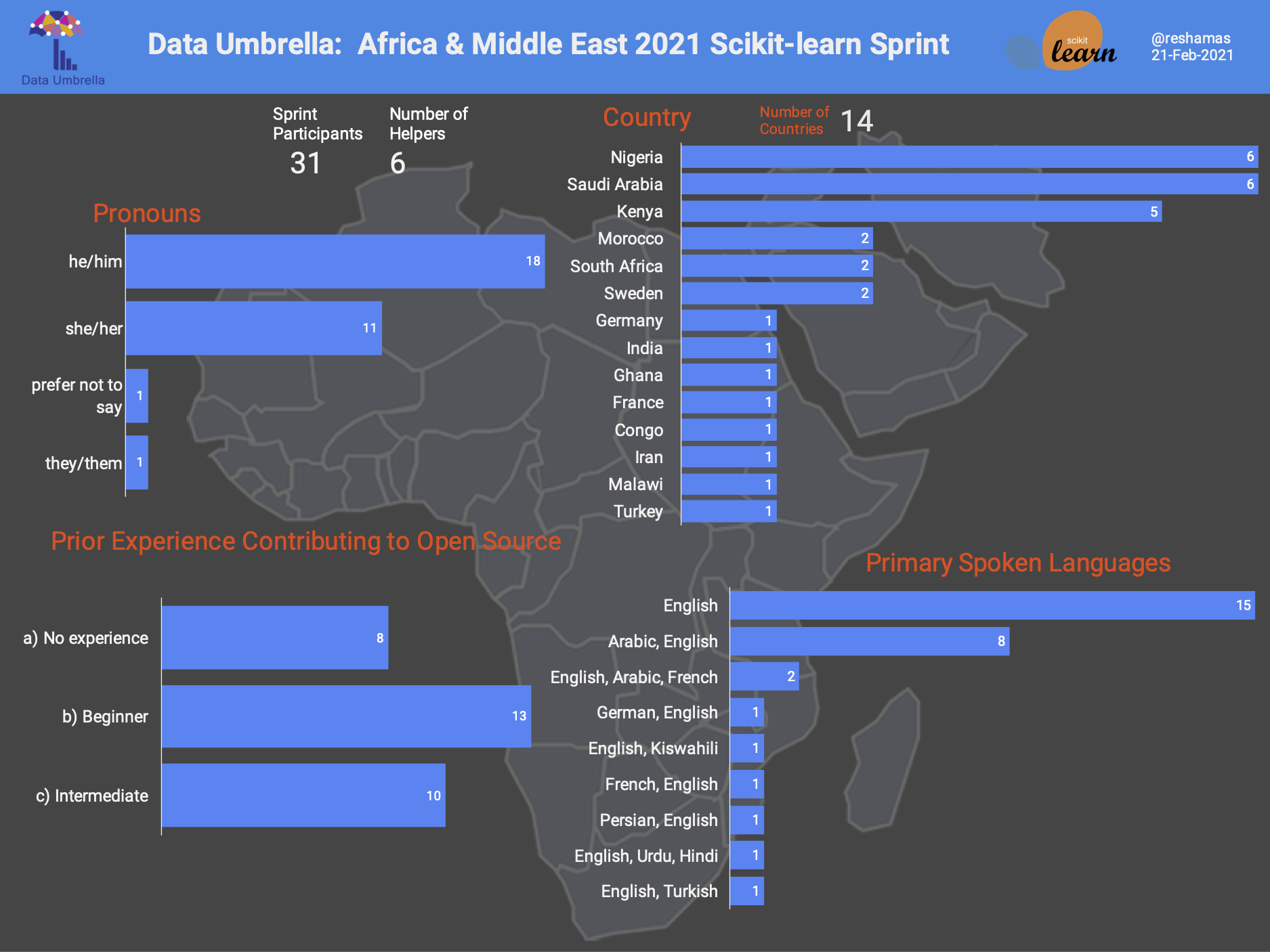
A total of 31 contributors attended the sprint. 12 of 31 (39%) identified as women or non-binary. 18 of 31 (58%) identified as men.
Contributors joined from 14 different countries. Country information was provided based on where participants were joining from. Saudi Arabia, Kenya and Nigeria had the most participants, for a total of 16 of 31, almost 55%.
Other countries represented include Morocco, South Africa, Ghana, Iran, Congo, Malawi, as well as Sweden and France.
Given the migration in the region, these other countries were also represented in terms of contributor background: Sudan, Turkey, Syria.
There were two invited contributors, joining from India and Germany. Invited contributors were those who participated in a prior sprint and have continued contributing to scikit-learn. They were paired with a new contributor.
Applications Received
The countries in the AFME region with the most applicants are:
- Nigeria: 20
- Kenya: 12
- Saudi Arabia: 8
- South Africa: 5
- Sweden: 4
- Morocco: 4
Spoken Languages
All communication was in English. All participants felt comfortable conversing in English. Languages spoken by participants included: English, Arabic, French, Kishwahli, Persian, Hindi, Urdu, Turkish and German.
Open Source Background
Two-thirds of participants identified as having “none” or “beginner” level experience in contributing to open source.
Number of Participants
- About 15 participants joined the pre-sprint event
- 31 participants joined the sprint
- 7 participants joined the post-sprint event
Impact Report for Data Umbrella Scikit-learn Sprint
| Sprint 2020 | ||
|---|---|---|
| Report date | 28-Feb-2021 | |
| Report author | Reshama Shaikh | |
| Sprint date | 06-Feb-2021 | |
| Location | Online; Africa & Middle East (AFME) | |
| Sprint website | afme2021.dataumbrella.org | |
| Twitter Moment | ||
| Open source library | scikit-learn | |
| GitHub repository link | data-umbrella/data-umbrella-scikit-learn-sprint | |
| Organizers | Reshama Shaikh & Mariam Haji | |
| Lead Facilitator | Andreas Mueller | |
| Scikit-learn core contributors | Adrin Jalali, Olivier Grisel, Guillaume LeMaitre | |
| Invited Contributors | Amanda D’Souza & Maren Westerman | |
| Teaching Assistants | None | |
| Platforms | Discord & Zoom | |
| Sponsor: | Grant GBMF8449 from Gordon and Betty Moore Foundation & Code for Science and Society | |
| PULL REQUESTS (PRs) | ||
| PRs [MRG] at sprint | 7 | |
| PRs [MRG] post-sprint | 3 | |
| PRs open | 9 | |
| Attendees: Initial Registrations | 45 | |
| Attendees: Participated | ~ 31 | |
| Attendee List | Sprint Contributors | |
| Post-sprint Survey | [survey form] (closed) | |
| Blog: by Fortune Uwha | First Time Contributor to Open Source — Data Umbrella Scikit-learn Virtual Sprint February 2021 |
Resources for Contributing to scikit-learn
Because this was a virtual event and there is a limited capacity for being online for a full 8-hour day, a checklist was provided so folks could do preparation work at their own pace prior to the sprint.
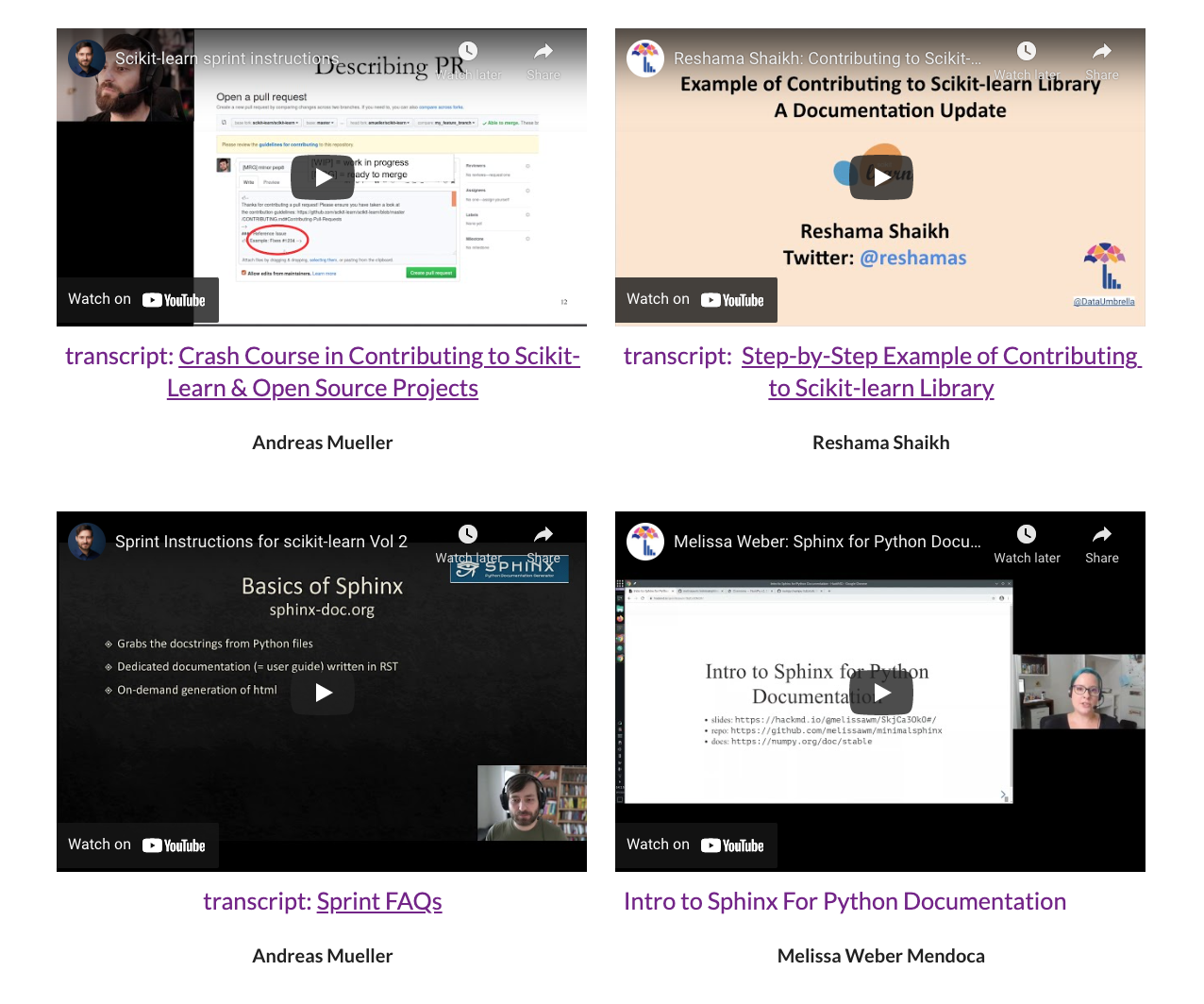
Videos
Here are some videos in a playlist that provide useful information on contributing to scikit-learn.
Checklist
Here is a Checklist to begin contributing to scikit-learn. Interested contributors can organize their own sprint, work with a pair programming partner or work on their own. Click on the image and it will link to a document that can be copied and edited for individual use.

Impact
Non-measurable Impact
Aside from the number of PRs that were merged, there is non-quantifiable impact of the open source sprint. Some examples include:
- learning to set up virtual environment
- using Git (fork, clone, branch, fetching another’s PR)
- introduction to tests such as: flake8 (linting, formatting), pytest, “continuous integration”
- navigating through the codebase structure of scikit-learn
- digging into functions, learning about errors
- learning about unit tests
- interacting with contributors on GitHub
- learning, in general
- networking
- building confidence (making a dent in “imposter syndrome”)
- having fun
Documentation Impact
These are the statistics for the videos that are considered documentation:
- Andreas Mueller: Crash Course in Contributing to scikit-learn
- Jan 1, 2021: 1100
- Mar 1, 2021: 1600 (+500 views)
- Reshama Shaikh: Example of scikit-learn Pull Request
- Jan 1, 2021: 545
- Mar 1, 2021: 745 (+200 views)
- Andreas Mueller: Sprint FAQs
- Mar 7, 2021: 398
- Reshama Shaikh: Intro to Discord
- Mar 7, 2021: 99
Sprint outreach can be considered an impact. Even if folks do not attend or apply, the sprint outreach brings more visibility and interest to the project.
Contributing to Other Libraries Post-Sprint
One sprint participant used his open source skills to contribute to another Python library.
Event Outreach
This tweet had 90K+ impressions and 320 link clicks:
📣Join us for our #ScikitLearnSprint
— Data Umbrella (@DataUmbrella) January 5, 2021
👉🏽with a focus on Africa & Middle East (AFME)
🗓️06-Feb-2021
🕙10am to 2pm EAT
🏢 Online
Thank you to our sponsors: @codeforsociety & @MooreFound
Details on application: https://t.co/TOMAJpkcF0 pic.twitter.com/oXq4yjq3XI
This LinkedIn post had ~2500 views and 35 shares:
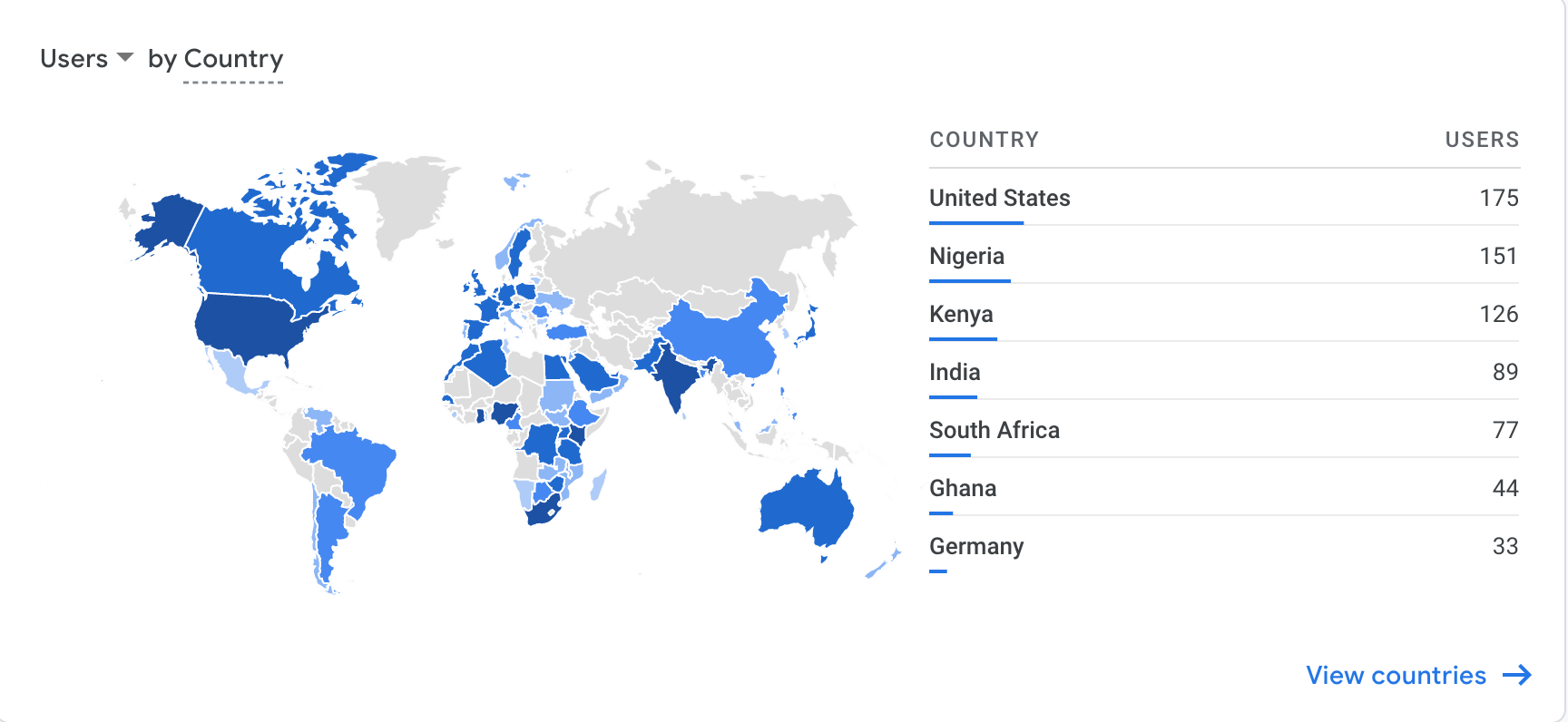
Google Analytics shows the reach of our marketing efforts:
Adjustments for Next Sprint
Reviewing Pull Requests
Reviewing PRs will also be added on the list of issues that the sprint participants can work on.
For sprint attendees who have submitted a PR, then can review other contributor’s PRs and provide feedback.
Video: Reviewing PRs
Create a video that shows how contributors can review PRs with tips.
scikit-learn branch: “master” to “main”
Include a note that scikit-learn has changed their default branch name from “master” to “main”. Currently all the videos and documentation refer to “master.”
Applicant Attrition
We typically observe 10% no-show rates for this type of online event. For this event it was much higher. For future sprints, we will do more outreach, aim for more applications so that overall turnout is about 40 attendees.
#DataUmbrella Hashtag
Reminder to sprint participants to include this hashtag #DataUmbrella on their pull requests so we can track them.
Post any questions on #help_queue channel on Discord
A number of sprint participants were waiting alone at their virtual table. They did not proactively join the #help_queue channel to let us know their pair programming partner was not present. We should include a reminder for this in our email communications and intro presentation.
Time of Event
Due to availability of the lead organizer and scikit-learn core contributor, the sprint began at 8am WET (Western European Time), which was 8am Nigeria / West Africa time. That is likely too early for a Saturday event. Schedule event so focused participants begin at 9am or 10am at the earliest.
Sprint Feedback
Feedback has been shared a number of ways:
- Twitter Moment
- Blogs
- Sprint survey
- Social media (LinkedIn)
- Casually, in conversation during the sprint, pre-sprint and post-sprint events
Data Umbrella Feedback Survey
Data Umbrella received 21 responses to our internal sprint survey. (21/31 = 68% response rate).
Respondents rated their overall sprint experience highly favorably and had a positive experience working with their pair programming partner.
In response to the question “What are your favorite parts about the sprint?”
- Pair programming
- Getting to directly interact with sklearn’s core contributors.
- Working on issues and collaborating with my partner.
- The amazing feeling of being part of a large community that cares.
- Meeting people from different countries
- Overall good arrangement + the presence of core-contributors to support through the whole process from setting the development environment to submitting and merging a PR
- Meeting new people and getting to know core team
- Getting to meet the core contributors to sckit-learn. So helpful and friendly!
- Pair programming, an Excellent sprint strategy
- The communication with my pair programming partner
- The community is great and friendly
- The pair programming and the feedback session with the core developers
- There was ample knowledge to start working on things. It was very easy to get going with the shared information.
- Working on an issue with a partner alongside a contributor. I got a better perspective on working on issues.
- Getting help from the core contributors/developers and learning from my programming partner
- discussing details of technical problems and solutions in small groups on discord / github
Some general feedback in the survey:
- I had a very good pair programming partner from a different country and profession. The sprint was planned very well. I definitely would love to participate in more of such sprints.
- The experience was amazing and worth it I really learnt a lot and hopefully to keep up on working on more OS. Love the diversity and networking that comes along with am proud to have collaborated with my pair and contribution on the OS thank you for the great platform.
One suggestion for improvement:
- Have single comprehensive source of information for preparing the environment.
Social Media
Mabu
Fortune
Congrats @fortune_uwha! 🌟🌟
— Data Umbrella (@DataUmbrella) February 6, 2021
> LGTM. Adding tests as a first time contributor, respect! pic.twitter.com/wE6qdHHkHb
First time contributor to open source/scikit learn 🎉🎉. The #ScikitLearnSprint session was so much fun! We got a chance to meet the core contributors. Super grateful to @codeforsociety and @MooreFound for supporting @DataUmbrellaAFR
— Fortune Uwha🦋 (@fortune_uwha) February 6, 2021
Submitted PR. 🤞on getting merged.@reshamas
Haidar
I got my first @scikit_learn PR merged it was a very small contribution but a big event for me
— Haidar AlMubarak (@HALMUBARAK) March 2, 2021
Thanks to @DataUmbrella for organizing the #ScikitLearnSprint
I might write a short description about my experience @ https://t.co/gwlHNy22yU pic.twitter.com/3uHaD80LzP
Amanda
As always, a great time at @DataUmbrella's #ScikitLearnSprint. Pair programming works! https://t.co/k6uVQsffL5
— amanda dsouza (@amanda_dsouza) February 6, 2021
Clifford
First time wrangling through the sklearn code base. The #ScikitLearnSprint session was enlightening. We met the core developers too. And my programming partner was ❤️❤️
— Clifford Emmanuel Akai-Nettey (@ce_akainettey) February 6, 2021
Thank you @DataUmbrellaAFR.
✌️ on the PR review though😅#opensource #python #datascience #MachineLearning
Maren
I'm very grateful for having been invited as a returning contributor to assist a first time contributor with getting a pull request submitted. My pair programming partner and I successfully made a PR. Fingers crossed our changes pass the tests and get merged. 🤞🏾 https://t.co/Lga4eIA67L
— Maren Westermann (@MarenWestermann) February 6, 2021
Ogbonna
Special thanks to the sponsors, core contributors @reshamas @glemaitre58 @xlorentzen @ogrisel for their guidance, assistance and enabling me to learn and contribute, and to my pair programmer, Rukuyat Amzat. #opensource #python #MachineLearning
— Ogbonna Chibuike (@OgbonnaChibuiks) February 10, 2021
Muhammad
Made my first open-source contribution last week, with 2 pull requests merged into the @scikit_learn project! 🥳🥳
— Muhammed Jarir Kanji (@mjkanji) February 11, 2021
Huge thanks to @DataUmbrella and @reshamas for organising the event and to @glemaitre58 and @ogrisel for guiding me through it!
Fortune
Two issues. Two PR approved and merged 🎉🎉. This sure feels good. Me and my pair programming partner(Cee thinwa) rock😁. Thanks to @ogrisel @reshamas @DataUmbrella for making this possible.
— Fortune Uwha🦋 (@fortune_uwha) February 12, 2021
Meanwhile, I wrote an article about my experience on medium. 👇 https://t.co/RoHLSSmM7S pic.twitter.com/kKQn3ItDkb
Congrats @fortune_uwha! 🌟🌟
— Data Umbrella (@DataUmbrella) February 6, 2021
> LGTM. Adding tests as a first time contributor, respect! pic.twitter.com/wE6qdHHkHb
Anas
very happy to be part of #ScikitLearnSprint, many thanks to @DataUmbrella for this amazing opportunity. https://t.co/M34gNPX5Qd
— anas (@hasnii_anas) February 6, 2021
Feras
Thank you @DataUmbrella @codeforsociety @MooreFound
— Feras O (@Feras_Oughali) February 6, 2021
for organizing #ScikitLearnSprint
It was a pleasure meeting you @reshamas and the great team!
Cindy
Thank you @DataUmbrella for organising a great sprint and to all the @scikit_learn contributors for supporting! #ScikitLearnSprint
— Cindy Bezuidehout (@CBezuidehout) February 7, 2021
Sohayb Elmraoui
Thank you Reshama Shaikh, Data Umbrella, Andreas Mueller, and Scikit-Learn team for organizing this event. It was a great opportunity meeting you all and contributing to the library. LI post
Feras
Thank you Reshama Shaikh, Data Umbrella, Andreas Mueller, and Scikit-Learn team for organizing this event. It was a great opportunity meeting you all and contributing to the library. LI post
Acknowledgments
- All the scikit-learn core contributors who mentored at the sprint and those who were online during the weekend afterwards to promptly review the submitted pull requests.
Pull Request Statistics
- PRs merged on sprint day: 7 (from AFME sprint)
- Query:
is:pr is:merged pr:merged:>=2021-02-06 pr:created:<=2021-02-07 #DataUmbrella
- Query:
- Open PRs: 9 (from AFME sprint)
- Query:
is:pr is:open pr:created:>=2021-02-06 pr:created:<=2021-03-01 #DataUmbrella
- Query:
- Open (w/o date range): 10
- Query:
is:pr is:open #DataUmbrella
- Query:
- Merged PRs: 19 (>= 2021-02-06)
- Query:
is:pr is:merged created:>=2021-02-06 #DataUmbrella
- Query:
- Merged (w/o date range): 79
- Query:
is:pr is:merged #DataUmbrella
- Query:
References
- List of Upcoming scikit-learn Sprints
- List of Past scikit-learn Sprints
- List of scikit-learn Sprints (compiled by Reshama Shaikh)
- scikit-learn Sprints Organized by Reshama Shaikh
Addendum
- [no addendums or updates at the time of publication]
Leave a Comment